Master Thesis
We offer several master thesis projects to the students following one of the master’s programs at the University of Namur. Those projects can cover one or more topics related to the research done at the SNAIL team or explore new directions. It is also possible to propose your own project related to our ongoing research. If you think you have a great idea, do not hesitate to contact us, but make sure you have clearly identified the research aspect and novelty of your proposal.
The project can be conducted at the computer science faculty, in collaboration with the members of the team, at another Belgian organization (industry, research center, university, …) with which we have an ongoing collaboration, or abroad at another university in our network.
If you study at a different university and you would like to do a research internship in the context of one of our projects, you should ask your own university supervisor to contact us. We have limited places available but are always interested in new research opportunities.
Master Thesis Projects
Current and Past Projects
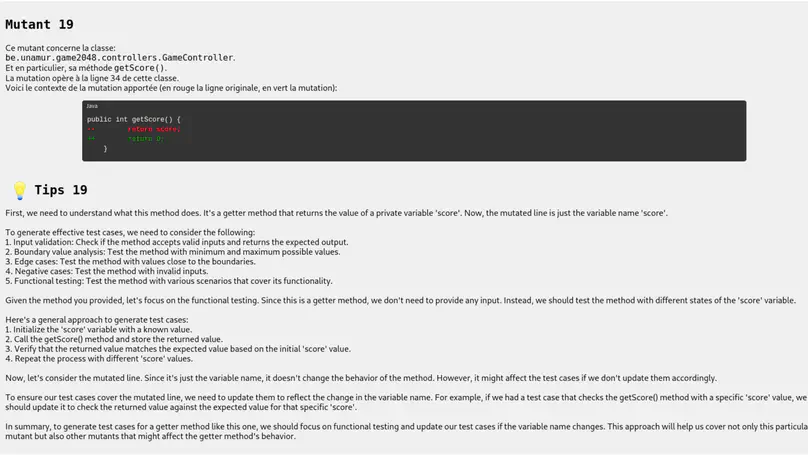
Researchers and practitioners have developed automated test case generators for various languages and platforms, each with different strengths. Comparing these tools requires large-scale empirical evaluations, which demand significant setup and analysis. The JUnit Generation benchmarking infrastructure (JUGE) automates the production and comparison of Java unit tests for multiple purposes, aiming to streamline evaluation, support knowledge transfer, and standardize practices. This master’s thesis will use the existing JUGE infrastructure to conduct an extensive empirical comparison of unit test generators for Java, and provide the resulting dataset to the research community.
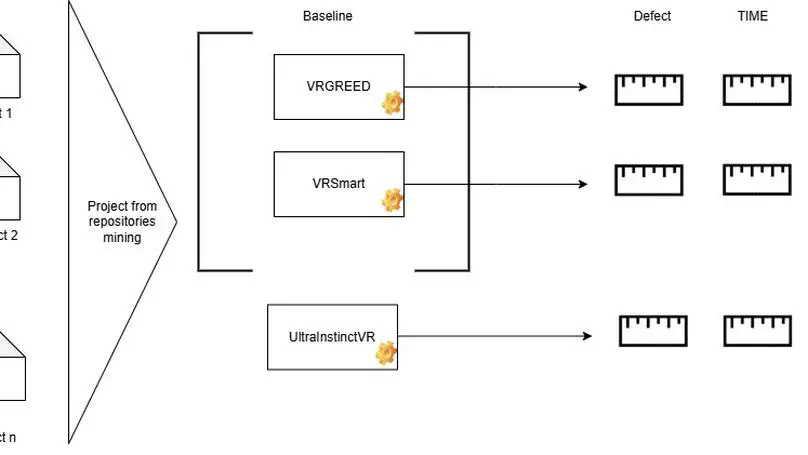
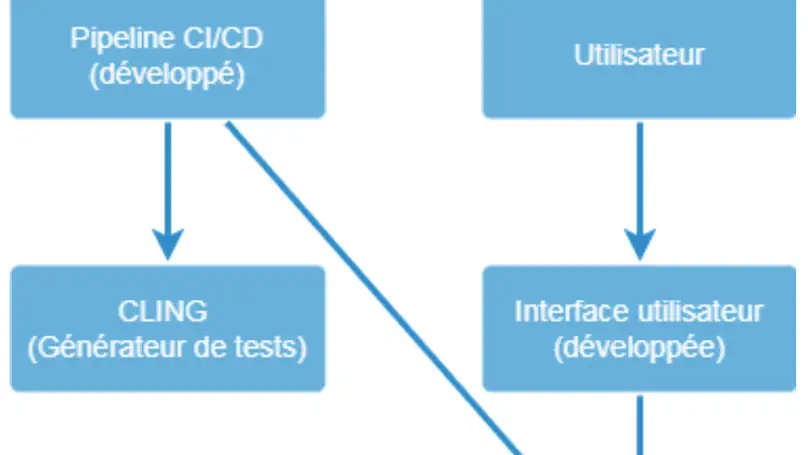
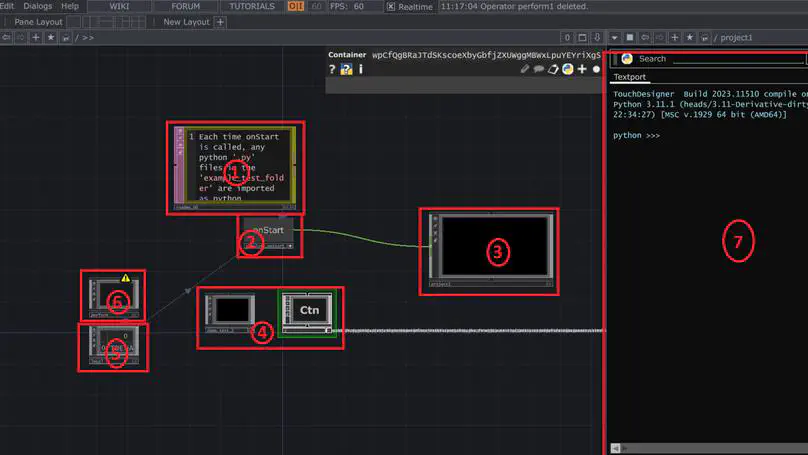
As creative coding in interactive art becomes increasingly popular in the digital art world, the need to test work to ensure that it matches the artist’s expectations is essential. The problem is that the programs supporting these works can behave unexpectedly or cause problems. Some studies have shown that is possible to test these projects manually, but the use of automated tests has been little studied. The research aims to explain to what extent it is possible to implement automated tests for functional and performance testing in interactive installation projects using hybrid development tools. To answer this question, we performed a case study on the Wall of fame project in TouchDesigner. Observations on automated test experiments and an interview were made. The results of the observations showed that it was possible to carry out functional and performance tests with limitations on the reliability of the data. Difficulties were identified : TouchDesigner dependencies, operator limitations, user interface interactions, lack of native test environments, performance test limitations and maintenance difficulties. Solutions have also been found to resolve these issues.



The field of automated test case generation has grown considerably in recent years to reduce software testing costs and find bugs. However, the techniques for automatically generating test cases for machine learning libraries still produce low-quality tests and papers on the subject tend to work in Java, whereas the machine learning community tends to work in Python. Some papers have attempted to explain the causes of these poor-quality tests and to make it possible to generate tests in Python automatically, but they are still fairly recent, and therefore, no study has yet attempted to improve these test cases in Python. In this thesis, we introduce 2 improvements for Pynguin, an automated test case generation tool for Python, to generate better test cases for machine learning libraries using structured input data and to manage better crashes from C-extension modules. Based on a set of 7 modules, we will show that our approach has made it possible to cover lines of code unreachable with the traditional approach and to generate error-revealing test cases. We expect our approach to serve as a starting point for integrating testers’ knowledge of input data of programs more easily into automated test case generation tools and creating tools to find more bugs that cause crashes.