SelfBehave, Generating a Synthetic Behaviour-Driven Development Dataset Using SELF-INSTRUCT
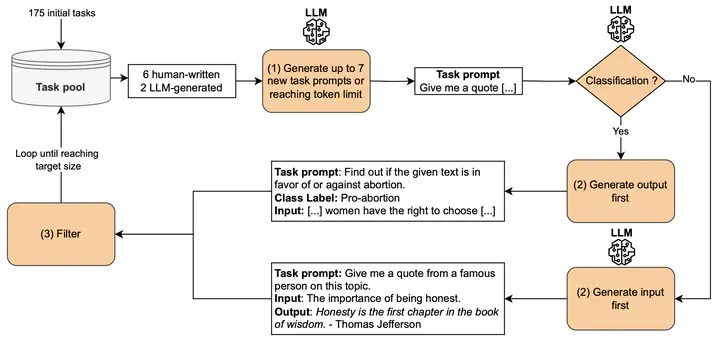 SELF-INSTRUCT process
SELF-INSTRUCT processAbstract
While state-of-the-art large language models (LLMs) show great potential for automating various Behavioral-Driven Development (BDD) related tasks, such as test generation, smaller models depend on high-quality data, which are challenging to find in sufficient quantity. To address this challenge, we adapt the SELF-INSTRUCT method to generate a large synthetic dataset from a small set of human-written high-quality scenarios. We evaluate the impact of the initial seeded scenarios’ quality on the generated scenarios by generating two synthetic datasets: one from 175 high-quality seeds and one from 175 seeds that did not meet all quality criteria. We performed a qualitative analysis using state-of-the-art quality criteria and found that the quality of seeds does not significantly influence the generation of complete and essential scenarios. However, it impacts the scenarios’ capability to focus on a single action and outcome and their compliance with Gherkin syntactic rules. During our evaluation, we also found that while raters agreed on whether a scenario was of high quality or not, they often disagreed on individual criteria, indicating a need for quality criteria easier to apply in practice.
Martin Balfroid
PhD Student
Benoît Vanderose
Professor of Software Engineering
Xavier Devroey
Professor of Software Engineering
My research goal is to to ease software testing by exploring new paths to achieve a high level of automation for test case design, generation, selection, and prioritization. My main research interests include search-based and model-based software testing, test suite augmentation, DevOps, and variability-intensive systems.