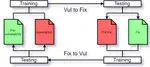
Multiple techniques exist to find vulnerabilities in code, such as static analysis and machine learning. Although machine learning techniques are promising, they need to learn from a large quantity of examples. Since there is not such large quantity of data for vulnerable code, vulnerability injection techniques have been developed to create them. Both vulnerability prediction and injection techniques based on machine learning usually use the same kind of data, thus pairs of vulnerable code, just before the fix, and their fixed version. However, using the fixed version is not realistic, as the vulnerability has been introduced on a different version of the code that may be way different from the fixed version. Therefore, we suggest the use of pairs of code that has introduced the vulnerability and its previous version. Indeed, this is more realistic, but this is only relevant if machine learning techniques can properly learn from it and the patterns learned are significantly different than with the usual method. To make sure of this, we trained vulnerability prediction models for both kind of data and compared their performance. Our analysis showed a model trained on pairs of vulnerable code and their fixed version is unable to predict vulnerabilities from the vulnerability introducing versions. The same goes for the opposite, despite both models are able to properly learn from their data and detect vulnerabilities on similar data. Therefore, we conclude that the use of vulnerability introducing codes for machine learning training is more relevant than the fixed versions.