Application Programming Interfaces, known as APIs, are increasingly popular in modern web applications. With APIs, users around the world are able to access a plethora of data contained in numerous server databases. To understand the workings of an API, a formal documentation is required. This documentation is also required by API testing tools, aimed at improving the reliability of APIs. However, as writing API documentations can be time-consuming, API developers often overlook the process, resulting in unavailable, incomplete or informal API documentations.
Recent Large Language Model technologies such as ChatGPT have displayed exceptionally efficient capabilities at automating tasks, disposing of data trained on billions of resources across the web. Thus, such capabilities could be utilized for the purpose of generating API documentations.
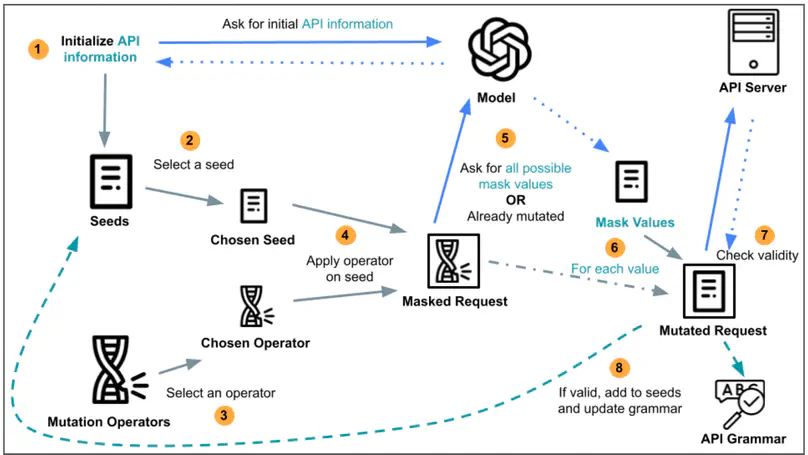
Therefore, the Master’s Thesis proposes the first approach Leveraging Large Language Models to Automatically Infer RESTful API Specifications. Preliminary strategies are explored, leading to the implementation of a tool entitled MutGPT. The intent of MutGPT is to discover API features by generating and modifying valid API requests, with the help of Large Language Models.
Experimental results demonstrate that MutGPT is capable of sufficiently inferring the specification of the tested APIs, with an average route discovery rate of 82.49% and an average parameter discovery rate of 75.10%. Additionally, MutGPT was capable of discovering 2 undocumented and valid routes of a tested API, which has been confirmed by the relevant developers.
Overall, this Master’s Thesis uncovers 2 new contributions: