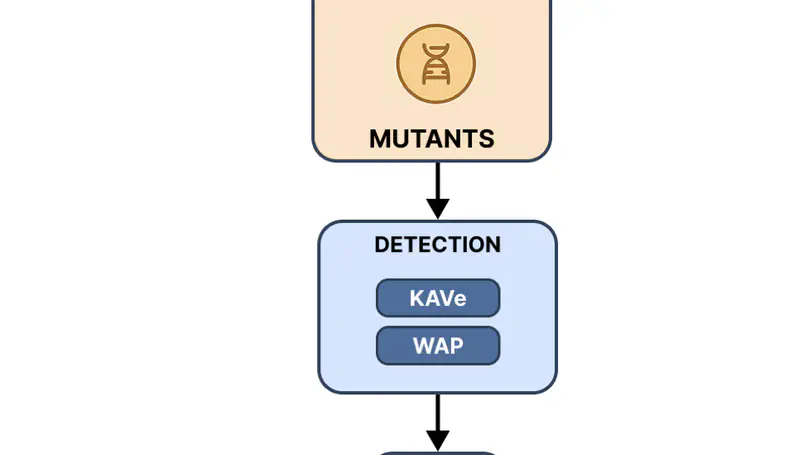
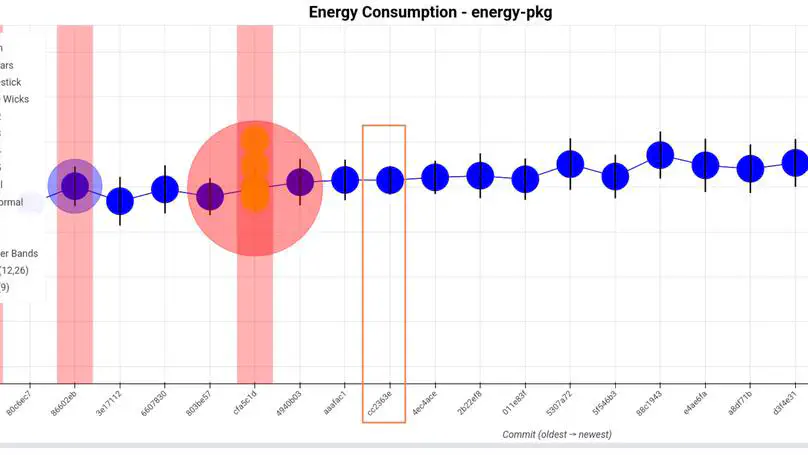
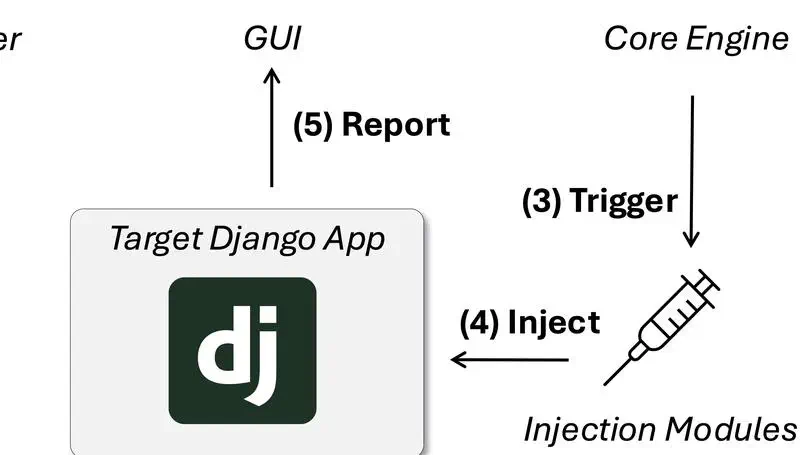
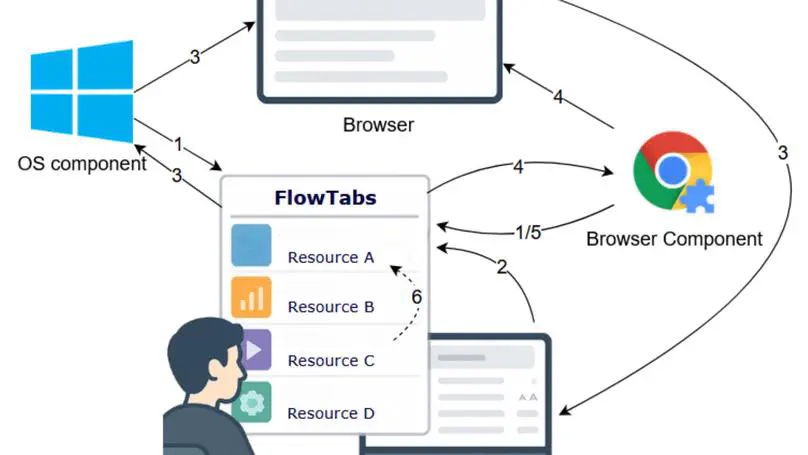
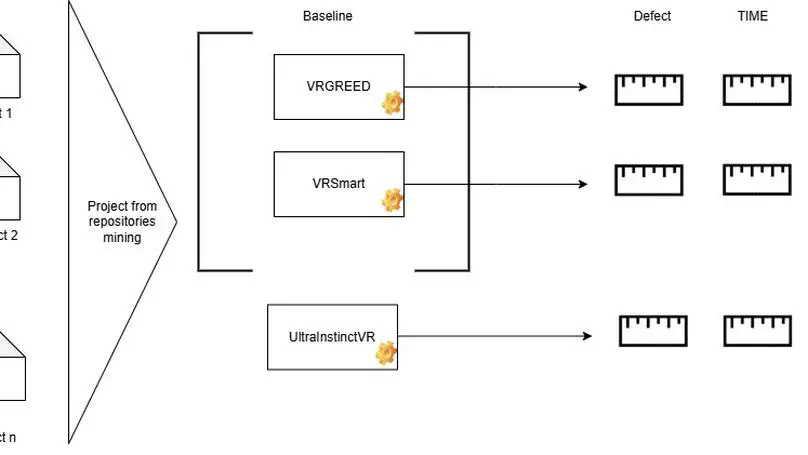
Looking after bugs and vulnerabilities is one of the most important tasks in computer science, especially in the context of web applications. There are many techniques to detect and prevent these issues, one of the most widely used being mutation testing. However, creating mutants manually is a time-consuming and error-prone pro- cess. To address this, we perform a combination of static analysis and an LLM to automatically generate mutants. In this study, we compare the performance of an LLM in producing mutants based on three different static analysis tools: KAVe, WAP, and the LLM itself. Our results show significant variability between tools. Mutants produced using traditional static analysers vary heavily depending on the type of vulnerability, and tend to perform better when tools are combined. When it comes to the LLM, the quality of mutants is more consistent across different vulnerabilities, and the overall code coverage is significantly higher than traditional approaches. On the other hand, LLM-generated mutants have a higher success rate in passing initial verification, but often contain syntactic or semantic errors in the code. These findings suggest that LLMs are a promising addition to automated vulnerability testing workflows, especially when used in conjunction with static analysis tools. However, further refinement is needed to reduce the generation of incorrect or invalid code and to better align with real-world exploitability.