SelfBehave: Generating a Behaviour-Driven Development Dataset Using the SELF-INSTRUCT Method
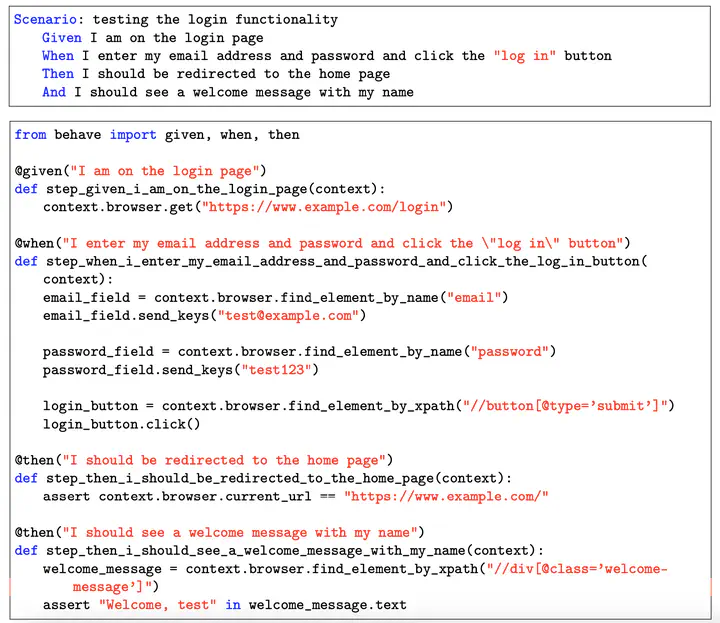 Generated scenario and corresponding implementation
Generated scenario and corresponding implementationSoftware development faces persistent challenges in terms of maintainability and efficiency, and this is driving the ongoing search for innovative approaches. Agile methodologies, in particular Behaviour-Driven Development (BDD), have gained ground in society thanks to their ability to promote responsiveness to change and communication between stakeholders. However, as with many methods, the use of BDD can lead to mainte- nance costs and productivity problems. To meet these challenges, this research investigates the adaptation of advanced automatic data generation techniques, in particular SELF-INSTRUCT, to augment BDD datasets.
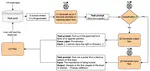
The research starts by analyzing the state of the art in Agile methodologies, natural language processing (NLP) and automation tools, highlighting the limitations of existing approaches and the potential of the SELF- INSTRUCT method. Next, the methodology section details the adaptation of the method to the BDD context and the creation of datasets with different initial data quality. The results indicate that SELF-INSTRUCT effectively augments BDD datasets, doubling the size of the original dataset and producing usable scenarios. However, improvements are needed, particularly in the filtering phase, to improve the quality of the data generated and accepted by the method. In addition, the study reveals that the quality of the initial data influences the validity of the scenarios generated, with good quality seed producing a greater number of valid pairs. Nevertheless, all the sets studied resulted in usable scenarios, indicating the effectiveness of SELF-INSTRUCT regardless of seed quality. The research suggests ideas for future exploration, including further fine-tuning of the method and investigation of different language models.
In conclusion, this research confirms the potential of automated data generation techniques, such as SELF- INSTRUCT, to efficiently and substantially increase the size of sets composed of BDD data. Despite its limitations, this study lays the foundation for future research aimed at improving BDD dataset augmentation and advancing the field of automated data generation in software engineering.