Table of Contents
Une vaste majorité des processus que l’on trouve dans le monde de la science reposent sur l’examen par les pairs (peer review). Il s’agit de demander à des experts d’un domaine de recherche d’évaluer un article scientifique, un projet de recherche, le CV d’un scientifique, l’excellence académique d’une organisation, etc. Dans sa forme la plus simple, le processus fait intervenir trois rôles, un·e candidat·e, un·e arbitre et au moins deux expert·e·s. La candidature est soumise pour arbitrage, elle est envoyée aux expert·e·s qui produisent un rapport. Sur base de ce rapport, l’arbitre prend une décision.
Examen et publication d’un article scientifique
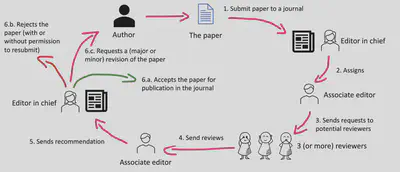
Pour un article scientifique, celui-ci est soumis par ses auteur·e·s pour publications auprès d’un journal ou d’une conférence. Dans le cas d’un journal, l’éditrice·eur (qui est en général un·e scientifique senior) va prendre contact avec au moins trois évaluateurs·rices et leur demander de lire et évaluer l’article sur base d’un ensemble de critères (plus ou moins) définis. Sur base des rapports écrits par les évaluateurs·rices, l’éditrice·eur prends une décision et accepte ou rejette l’article pour publication dans le journal. Iel peut aussi demander aux auteur·e·s de préparer une révision de leur article sur base des commentaires reçus et de soumettre cette révision pour une nouvelle évaluation. À noter qu’il est très courant que les articles passent par un, voire deux cycle(s) de révision et évaluation avant d’être acceptés pour publication.
Dans le cas d’une conférence, un appel ouvert est lancé afin que des auteur·e·s soumettent un article pour évaluation avant une date donnée. Une fois les articles soumis, les responsables du comité de programme de la conférence distribuent les articles à évaluer entre les différents membres du comité de programme préétabli. Sur base des rapports, les responsables décident d’accepter ou non les articles pour publications dans les actes de la conférence. À la différence des journaux, il est très rare que les conférences offrent la possibilité de réviser un article pour qu’il soit réévalué. S’il est rejeté, un article sera en général revu et resoumis à la même conférence ou à une conférence similaire.
Critères d’évaluation
Les critères d’évaluation d’un article dépendent grandement du journal ou de la conférence à laquelle il a été soumis. Par exemple, une petite conférence ou un atelier (workshop) privilégiera des articles suscitant le débat durant la conférence. L’évaluation empirique répondant aux questions de recherche de ces articles est souvent limitée. À l’inverse, une grande conférence ou un journal insistera sur la nécessité d’une évaluation plus importante afin de répondre de manière plus complète aux questions de recherche. Voici par exemple les critères d’évaluation donnés par l’International Conference on Software Engineering (ICSE) :
- Soundness: The extent to which the paper’s contributions and/or innovations address its research questions and are supported by rigorous application of appropriate research methods.
- Significance: The extent to which the paper’s contributions can impact the field of software engineering, and under which assumptions (if any).
- Novelty: The extent to which the contributions are sufficiently original with respect to the state-of-the-art.
- Verifiability and Transparency: The extent to which the paper includes sufficient information to understand how an innovation works; to understand how data was obtained, analyzed, and interpreted; and how the paper supports independent verification or replication of the paper’s claimed contributions.
- Presentation: The extent to which the paper’s quality of writing meets the high standards of ICSE, including clear descriptions, as well as adequate use of the English language, absence of major ambiguity, clearly readable figures and tables, and adherence to the formatting instructions provided.
Historiquement ICSE est la principale et la plus grande conférence de recherche en génie logiciel. Elle rassemble chaque année des scientifiques issu·e·s du monde entier et couvre les différentes thématiques du génie logiciel (AI and software engineering, Testing and analysis, Software analytics, Software evolution, Social aspects of software engineering, Requirements, modeling, and design, Dependability).
Empirical standards
Comme on peut le remarquer, les critères utilisés par ICSE ne sont pas extrêmement précis, ce qui peut amener à accepter ou rejeter un papier pour de mauvaises raisons. Par exemple, est-il légitime de rejeter un papier sur base de sa nouveauté (novelty) ou de son importance (significance) lorsque l’on sait que la plupart des grandes découvertes ont été, dans un premier temps, rejetées par le reste de la communauté scientifique ? Un autre problème soulevé par le processus de revue par les pairs actuel est lié à la compétence des évaluateurs par rapport au choix fait lors de la définition du protocole de recherche. Par exemple, un évaluateur ayant une vue principalement positiviste et étant habitué aux larges évaluations quantitatives est-il compétent pour évaluer un article suivant un protocole reposant sur des évaluation qualitatives (et reposant en général sur une philosophie interprétativiste) ? Afin d’éviter ce genre de biais lors de l’évaluation d’articles, la communauté de recherche du génie logicielle s’est récemment lancée dans un vaste effort de standardisation reposant sur deux éléments :
- La déclaration explicite par les auteurs des choix fait dans la définition de leur protocole de recherche et
- L’évaluation des articles sur base d’une grille d’évaluation spécialisée en fonction des caractéristiques du protocole de recherche.
Cet effort s’est traduit par la définition des Empirical Standards et d’un outil permettant de générer une grille d’évaluation : l’Empirical Standards Checklist Generator.
Règle d’or : Il n’y a rien de personnel, il s’agit de la recherche et uniquement de la recherche.
- En tant qu’auteur·e : ne jamais prendre les choses personnellement.
- En tant qu’évaluateur·rice : rédigez une critique sur l’article, pas sur les auteurs. *On n’écrit pas Les auteurs devraient décrire, mais L’article devrait décrire. Laissez de côté vos sentiments et convictions personnels (par exemple, “Je trouve ce sujet intéressant”).
- En tant que président du comité de programme ou éditrice·eur (adjoint), veillez à la qualité des évaluations. Cette étape est souvent omise par manque de temps, ce qui donne des évaluations qui sont parfois à côté de la plaque.
Dans tous les cas, l’objectif final est d’améliorer l’article.
Single-anonymous, double-anonymous et revue ouverte
Pour des raisons de confidentialité, mais aussi de biais cognitifs des évaluateurs envers les articles, il n’est pas toujours souhaitable que les évaluateurs connaissent l’identité des auteurs. À l’inverse, il n’est également pas toujours souhaitable que les auteurs connaissent l’identité de leurs évaluateurs. Il existe plusieurs types de processus de revue par les pairs. Nous en distinguerons trois :
Le single-anonymous est un processus de revue dans lequel les auteur·e·s ne connaissent pas l’identité des évaluateurs·rices, mais les évaluatrices·eurs connaissent l’identité des auteur·e·s. Il a l’avantage de donner aux évaluatrices·eurs toute liberté de commenter un article sans craindre un retour de bâton (supposé) des auteur·e·s si, dans le futur, ceux-ci devenaient évaluateurs·rices d’un article soumis par un de leurs évaluateurs·rices passé. Le single-anonymous a longtemps été le standard de nombreuses conférences en génie logiciel. Malheureusement, il n’empêche par les à priori positifs ou négatifs que les évaluateurs·rices auraient sur les auteur·e·s et qui les influenceraient dans un sens ou dans l’autre (par exemple, le cas d’un article écrit par un sommité reconnue d’un domaine de recherche).
Pour réduire les problèmes de biais, de nombreuses conférences sont passées à un processus double-anonymous dans lequel les auteur·e·s ne connaissent pas leurs évaluateurs·rices et les évaluateurs·rices ne connaissent pas l’identité des auteur·e·s. Il s’agit bien évidement d’un processus dit de best-effort, durant lequel les auteur·e·s s’engagent à écrire leur article de telle manière à ce que leur identité ne soit pas dévoilée (par exemple, en retirant leur nom de l’article ou en écrivant XYZ et al.’s work à la place de our previous work). Ce type de revue a malheureusement le désavantage de demander un travail plus important de la part des auteur·e·s pour préserver leur identité secrète, non seulement dans l’article soumis, mais également dans les replication packages (contenant des données, scripts d’analyse statistiques, etc.) qui l’accompagneraient.
Un troisième type de processus propose de prendre le contrepied du anonymous-reviewing et d’ouvrir les revues. Dans un processus de revues ouvertes, les évaluatrices·eurs connaissent l’identité des auteur·e·s, et les auteur·e·s connaissent l’identité des évaluateurs·rices. Il est généralement admis que ce type de processus pousse aussi bien les auteurs que les évaluateurs à fournir des articles et des évaluations de meilleure qualité, celles-ci devenant publiques par la suite.
Resources additionnelles
- Empirical Standards Checklist Generator
- Reviewing a CS conference paper
- ACM Policy on Plagiarism, Misrepresentation, and Falsification
- ICSE 2023 Review Process and Guidelines
Artefacts
- Zenodo, un repository ouvert pour archiver les artefacts, jeux de données, vidéos, etc.
- Artifact Evaluation: Tips for Authors
- How to disclose data for double-blind review and make it archived open data upon acceptance
- Anonymous GitHub pour anonymiser facilement les repository GitHub.