Table of Contents
Répondre aux questions de recherche et tester les hypothèses demande dans la plupart des cas d’une part de collecter des données et d’autre part d’appliquer un traitement à ces données (par exemple, une analyse statistique). Les questions et hypothèses de recherche donnent des renseignements sur ce qui sera mesuré (par exemple, la couverture de code ou le temps mis pour produire des tests), sur les types de sujets considérés (par exemple, un benchmark ou des développeurs) et la raison de cette mesure (par exemple, comparer plusieurs approches de génération de tests). Elles ne donnent par contre aucune indication sur la manière de collecter et traiter les données. Pour se faire, il faut définir et décrire un protocole expérimental (ou méthode).
Définir une méthode permettant de répondre aux questions de recherche est une étape essentielle de la démarche scientifique. Une bonne méthode vise à maximiser le degré de confiance que l’on peut avoir dans le résultat d’une expérience (i.e., la validité des résultats). Le degré de confiance est généralement discuté dans une section spécifique des articles scientifiques. Cette section est souvent intitulée ``Threats to the validity’’ et discute les différents aspects qui pourraient influencer les résultats obtenus.
Dans notre exemple sur la génération automatique de tests, il faudra entre-autres veiller à garantir un traitement équitable entre les approches de base et l’approche XYZ. Cela passe par différents aspects, dont :
- La sélection d’un benchmark représentatif (il faudra définir ce que veut dire représentatif dans le contexte de l’évaluation) pour ne pas favoriser un type d’approche par rapport à l’autre,
- Une configuration correcte des différents outils sur base de l’objectif de l’évaluation,
- L’exécution des approches sur des machines avec une configuration similaire (il n’est par exemple pas question d’exécuter une approche sur un PC portable et l’autre approche sur un serveur de calcul),
- Lorsque l’évaluation se fait avec des développeurs, il faut s’assurer que les différents groupes soient de niveau de compétence égaux (il n’est par exemple par question d’utiliser une approche avec uniquement des développeurs junior et une autre approche avec uniquement des développeurs expérimentés),
- La sélection de tests statistiques adaptés aux données (il n’est par exemple pas question d’utiliser des tests statistiques qui supposent une distribution normale des données sans vérifier au préalable que les données considérées ont une telle distribution),
- etc.
Méthode et méthodologie
Comme on peut le voir dans notre exemple, définir une méthode d’évaluation nécessite de prendre un certain nombre d’aspects en compte. Heureusement, il n’est pas nécessaire de repartir de rien pour chaque nouvelle expérience et les scientifiques s’appuient sur des outils méthodologiques pour définir une méthode qui correspondent à leurs questions de recherche.
La méthodologie en science est l’étude de l’ensemble des méthodes scientifiques (c’est la méthode des méthodes). Elle permet de systématiser un certain nombre d’éléments de collecte et de traitement des données afin de maximiser le degré de confiance que l’on peut avoir dans le résultat d’une expérience.
Cette systématisation offre un autre avantage : elle permet de reproduire une expérience décrite dans un article scientifique dans un autre contexte afin de valider (ou non) les résultats qui y sont présentés. Lorsqu’une expérience a été reproduite un certain nombre de fois avec des résultats qui sont cohérents entre eux, l’on arrive à ce que l’on appelle un consensus sur une question de recherche, qui devient alors une connaissance communément admise par la communauté de recherche concernée.
Définition d’une méthode
La définition d’une méthode permettant de répondre aux questions de recherche peut se voir comme une série de choix fait à différents niveaux d’abstraction. Saunders et al. ont représenté ces choix dans un modèle en oignon, où chaque couche précise un peu plus la méthode utilisée par rapport à la couche qui l’englobe.
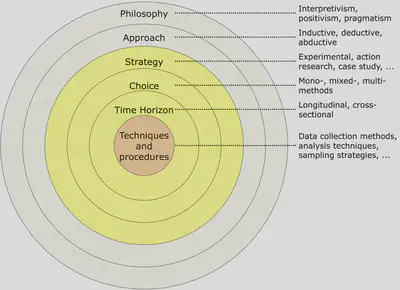
Les deux couches les plus externes de l’oignon s’intéressent à la manière dont la connaissance (Philosophy) et les théories (Approach) se construisent. Ces éléments sont souvent propres à un domaine ou un sous domaine de recherche. Les trois couches suivantes s’intéressent à la ou les méthodes choisies et leur mise en œuvre au travers du temps. Enfin, le cœur de l’oignon constitue le protocole de recherche répondant à la problématique traitée avec la définition concrète des différents outils (par exemple, les questionnaires à destination des développeurs, les outils de mesure de la couverture de tests, etc.) et la manière dont ceux-ci seront appliqués (par exemple, le moment auquel les développeurs répondent, le temps d’exécution alloué aux outils de génération de tests, etc.).
Philosophies
Il existe un certain nombre de philosophies de recherche. Pour ce séminaire d’introduction à la démarche scientifique, nous en retiendrons trois parmi les plus courantes.
Positivisme
Les positivistes adoptent une position selon laquelle la connaissance est unique et est construite à partir d’observations objectives de la réalité. Les scientifiques se contentent d’observer sans interpréter. Ce type de recherche utilise principalement des méthodes empiriques quantitatives dans lesquelles un nombre important de sujets sont observés et mesurés.
Dans notre exemple, la comparaison des différentes approches de génération de tests du point de vue de la couverture du code et du score de mutation aura tendance à suivre une philosophie positiviste. Le protocole comprendra alors un grand benchmark de programmes et des mesures indépendantes sur ces programmes et les tests générés.
Interprétativisme
Les interprétativistes se situent à l’opposé des positivistes. Si le positivisme est adapté à l’étude de phénomènes physiques (i.e., natural sciences), les interprétativistes considèrent que les humaines et leur environnement social ne peuvent pas s’étudier de la même manière. En effet, les différentes influences socio-culturelles d’une époque donnée font qu’un même évènement sera interprété différemment et aura différentes significations possibles, menant à différentes réalités (sociales). Pour les interprétativistes, les scientifiques jouent un rôle actif (et donc subjectif) en interprétant les données collectées au moyen de méthodes qualitatives. Les études interprétativistes pousseront généralement les analyses assez loin en se focalisant sur un petit nombre de sujets.
Dans notre exemple, la compréhension des différents facteurs menant un développeur à produire des tests plus efficaces plus rapidement en utilisant une approche de génération de tests automatique au travers de questionnaires et d’interviews aura tendance à suivre une philosophie interprétativiste. Le protocole comprendra alors des questions quant à l’expérience du développeur et à son niveau d’expertise par rapport aux tâches qui lui sont demandées.
Pragmatisme
Les pragmatiques ne sont pas limités à une seule approche philosophique. Ils soulignent l’importance d’utiliser les meilleurs outils à disposition pour étudier un phénomène dans son contexte particulier. Pour les pragmatiques, une démarche de recherche démarre par un problème et vise à apporter des solutions pratiques et à améliorer la pratique de manière plus générale. Un grand nombre de sujets de recherches en génie logiciel (dont le but est d’améliorer la pratique consistant à construire du logiciel) reposent sur une approche pragmatique.
Dans notre exemple, une approche pragmatique commencera par une étude quantitative sur un grand benchmark de programmes. Ensuite, sur base des résultats obtenus, l’approche tentera d’expliquer les facteurs favorisant ou non la génération automatique de tests en suivant une approche qualitative en analysant manuellement un sous ensemble des tests générés et en interprétant les observations faites.
Approches
Les approches dénotent la manière dont des scientifiques construisent leurs conclusions. Bien que rarement nommée tel quel dans les articles scientifiques, l’approche adoptée est néanmoins toujours présentée afin de renseigner le lecteur sur la manière dont les conclusions seront dérivées des données collectées.
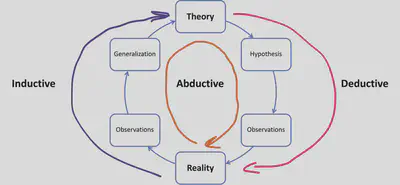
Déductive
Une approche déductive part d’une théorie afin de tester une série d’hypothèses au moyen d’une expérience. On part du général pour aller vers le spécifique.
Par exemple, il existe un grand nombre d’approches de génération automatique de tests qui se basent sur des algorithmes évolutifs. Ces algorithmes sont des heuristiques qui se basent sur la théorie de l’évolution de Darwin et qui considèrent qu’une solution optimale (ici, un test ou un ensemble de tests) peut être obtenue en faisant évoluer une population de solutions de base (par exemple, des tests générés aléatoirement). Notre exemple visant à évaluer la performance de différentes approches de génération de tests sur base de la couverture de code et du score de mutation suit une approche déductive : l’approche XYZ est issue de la théorie des algorithmes évolutifs et est testée et comparée à d’autres approches.
Inductive
Une approche inductive suite le raisonnement inverse. On part du spécifique pour aller vers le général. Une théorie est construite de manière itérative sur base d’un ensemble de données afin, par exemple, de pouvoir expliquer des effets.
Dans notre exemple, une approche inductive pourrait être appliquée sur base de données récoltées en observant et en questionnant des développeurs qui utilisent des approches de génération automatique de tests afin de construire une théorie expliquant comment ces outils interviennent dans un processus de test logiciel.
Abductive
Une approche abductive mélange induction et déduction. L’idée est ici de partir d’un fait ou d’une observation ``surprenante’’, d’en dériver une théorie possible et suffisante pour expliquer ce fait (induction) et d’ensuite tester cette théorie (déduction) et la raffiner.
Dans notre exemple sur la génération automatique de test, une approche abductive pourrait être appliquée pour construire une théorie expliquant pourquoi certaines approches sont plus efficace pour détecter certains types de fautes dans les programmes. L’approche démarrerait du fait ``surprenant’’ que certaines fautes ne sont détectées qu’au moyen d’une approche en particulier et testerait ensuite cette théorie en essayent de générer des tests pour d’autres fautes du même type.
Stratégies
Sur base de la philosophie de recherche et de l’approche choisie, il est possible d’utiliser une ou plusieurs stratégies. Ces stratégies définissent la manière dont les scientifiques vont collecter les données pour répondre aux questions de recherche.
Expérience
Une expérience (experiment) est utilisée pour mesurer l’effet d’une intervention (par exemple, le mise en place d’une nouvelle méthode de développement et de test) sur un groupe d’individus. Une variable dite indépendante est modifiée (par exemple, l’approche de génération de tests à utiliser : manuelle, XYZ, A, B, C) pour différents groupes d’individus (par exemples, différentes équipes de développeurs), tandis qu’une autre variable (dite dépendante) est mesurée (par exemple, le nombre de fautes trouvées par les développeurs) pour évaluer les effets du traitement. Une expérience (contrairement à un cas d’étude ou à une recherche-action) se déroule dans un environnement contrôlé tel qu’un laboratoire.
Une expérience comporte en général un groupe d’individus, appelé groupe contrôle ou groupe témoin, sur lequel aucune intervention n’est appliquée afin de s’assurer que les effets observés soient bien dû au traitement et non à un autre facteur externe. Une expérience dans laquelle aucun groupe contrôle n’est utilisé, est appelée une étude comparative (comparative study).
Sondage
Un sondage (survey) consiste en la collecte d’information auprès d’un sous-ensemble d’une population. Un sondage se fait généralement au moyen d’un questionnaire qui pourra contenir des questions ouvertes ou non. Un sondage peut être utilisé pour identifier (explorer) de nouveaux concepts (par exemple, quels sont les caractéristiques d’un test importantes aux yeux des développeurs), décrire les caractéristiques d’une population (par exemple, comment se réparti le niveau d’expertise d’un ensemble de développeurs) ou expliquer et tester une théorie (par exemple, les développeurs préfèrent les tests générés par l’approche XYZ par rapport aux tests générés par les approches A, B, C). À noter qu’un sondage peut aussi prendre la forme d’une interview dans laquelle les questions peuvent être complètement définies à l’avance (interview fermée) ou non (interview ouverte).
Cas d’étude
Un cas d’étude (case study) concentre l’étude sur un phénomène, un individu, un groupe d’individus ou une organisation pour en tirer une compréhension en profondeur. Tout comme un sondage, elle peut identifier de nouveaux concepts (par exemple, identifier les facteurs qui ont favorisé l’écriture de tests de haute qualité pour un projet de développement donné), décrire (par exemple, décrire le fonctionnement d’une équipe de développement) ou expliquer et tester une théorie (par exemple, l’introduction de l’outils XYZ dans une équipe de développement). Un cas d’étude utilisera en général un ensemble de techniques permettant de récolter des données à différents moments.
Recherche-action
De manière similaire à une étude comparative, une recherche-action (action-research) vise à introduire une ``action’’ (par exemple, l’utilisation d’un nouvel outil de test) dans un environnement. La différence vient du fait que la recherche-action demande une participation active des sujets durant les différentes étapes de la démarche de recherche (y compris l’identification du problème à résoudre). Le but d’une stratégie de recherche-action est donc d’avoir un impact qui soit à la fois théorique (en étendant le champ des connaissances), mais aussi pratique (en résolvant un problème existant). La démarche itérera plusieurs fois au travers des étapes suivantes jusqu’à ce que les résultats se stabilisent ou que le problème soit résolu :
- L’identification et la définition d’un problème à résoudre (diagnosing).
- La planification de différentes actions possibles à mener pour résoudre le problème (action planning).
- La sélection d’une action à mener (action taking).
- L’évaluation des résultats de l’action (evaluating).
- L’identification des résultats et des conclusions (specifying learning).
Dans notre exemple, une équipe de développement (accompagnée de scientifiques) désirant améliorer son processus de test suivrait une stratégie basée sur une recherche-action en essayant différentes approches de tests pour en tirer des enseignements et raffiner le processus de test à chaque itération.
Théorie ancrée
Les théories ancrées (grounded-theory) sont une méthode permettant de développer une nouvelle théorie de manière incrémentale en se basant sur ensemble de données collectées sur le terrain. Des données (le plus souvent qualitatives) sont analysées pour identifier des catégories importantes et les liens entre ces catégories. D’autres données sont collectées au fur et à mesure afin de raffiner la définition des catégories jusqu’à ce que l’on atteigne la saturation (le point à partir duquel inclure de nouvelles données n’apporte plus aucune nouvelle information).
Dans notre exemple, construire une théorie ancrée permettant d’expliquer comment une approche de génération automatique de tests est adoptée par une équipe de développement nécessiterait de partit d’un large ensemble de cas d’études et d’expériences pour lesquelles on a déjà collecté et analysé les données. Sur base de cet ensemble, les scientifiques vont traiter les différents résultats des expériences et cas d’études pour identifier les catégories de facteurs favorisant ou non la mise en place d’une approche de génération de tests.
Ethnographie
Une ethnographie (ethnography) est une stratégie dans laquelle les scientifiques vont observer un individu, un groupe ou une organisation de manière détachée sans intervenir. Cette observation peur se faire de manière contrôlée (en définissant les outils et protocoles d’observation) ou non.
Dans notre exemple, une ethnographie consisterait à observer la manière dont les développeurs produisent des tests, indépendamment du fait qu’ils utilisent des outils de génération automatisée ou non. Une telle étude permettrait d’identifier les pratiques en place au sein de l’équipe de développement (avant par exemple, de passer à un cas d’étude sur la mise en place d’un outil de génération automatique de tests).
Recherche d’archives
La recherche dans les archives (archival research) consiste à investiguer et examiner des documents existants (par exemple, des archives de rapports de projets de développement, des logs d’un système, les historiques de dépôts Git, etc.) afin d’en tirer des conclusions. Il est intéressant de noter que cette stratégie a connu un fort développement dans la recherche en génie logiciel avec le développement de l’open-source et des plateformes telles que GitHub où le code source, mais aussi les issues sont accessibles de manière ouverte.
Dans notre exemple, il serait par exemple possible d’extraire depuis les historiques de dépôts de code (mining software repositories) des programmes contenant des fautes, ainsi que les correctifs qui ont été appliqués afin de constituer un benchmark de programmes pour comparer les différentes approches de génération de tests.
Choix
Comme on peut le voir dans certains des exemples de la section précédente, il est possible d’utiliser et de combiner une ou plusieurs stratégies. Cela peut se faire pour différentes raisons : fournir un complément d’information, étendre la recherche pour approfondir certains résultats, trianguler des résultats afin de vérifier que les résultats issus de méthodes différentes convergent, etc. En fonction de la manière et du type de données récoltés, on parlera aussi de méthodes qualitatives ou quantitatives.
Méthodes quantitatives
Les méthodes quantitatives se concentrent sur la récolte de données chiffrées. Ces données sont généralement analysées par la suite en utilisant des méthodes statistiques afin de tirer des conclusions. Afin que ces conclusions soient solides, une méthode quantitative visera à collecter un grand nombre de données (couverture en largeur) au détriment de la finesse et de la profondeur de l’analyse effectuée.
Par exemple, comparer des approches de génération de tests sur base de la couverture et du score de mutation (uniquement) se basera sur des méthodes quantitatives. Cela nécessitera d’utiliser un grand benchmark avec un nombre important de programmes afin de garantir la robustesse des analyses statistiques.
Méthodes qualitatives
À l’inverse des méthodes quantitatives, les méthodes qualitatives se concentrent sur la récolte et l’analyse de données textuelles, visuelles, audio, etc. Ces données sont généralement analysées et interprétées par les scientifiques (identification de facteurs communs, regroupement en catégories, etc.) afin de tirer des conclusions. On appelle cette phase le codage : la transformation systématique de données qualitatives en données quantitatives selon un code (par exemple, l’association de labels à un ensemble d’images). Le codage peut être inductif (le code est développé à partir des données collectées) ou déductif (un code existant est appliqué et éventuellement adapté sur base des données collectées).
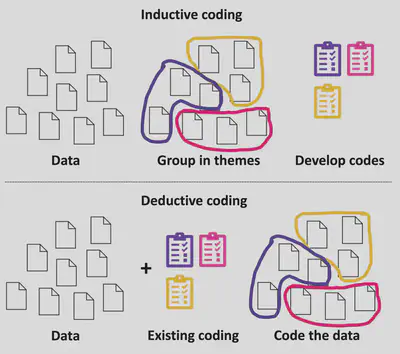
Afin que ces conclusions soient solides, une méthode qualitative visera un nombre restreint de données brutes pour pousser les analyses (couverture en profondeur) au détriment de la couverture en largeur. Par exemple, identifier les pratiques courantes de test au sein d’une ou plusieurs équipes de développement en menant des interviews avec les développeurs se basera sur des méthodes qualitatives. Cela nécessitera une interprétation des données (ici, les réponses des développeurs) menée ne parallèle par différents scientifiques de manière à minimiser les biais liés à la compréhension du texte.
Mono-méthode
Un protocole mono-méthode utilise, comme son nom l’indique, une seule méthode qui est soit quantitative, soit qualitative.
Méthodes mixtes
Un protocole mixte mélange en même temps des méthodes quantitatives et qualitatives. Il n’est pas exemple pas rare dans la recherche en génie logiciel de commencer avec une méthode quantitative pour identifier des tendances et catégories générales pour continuer par la suite avec une méthode qualitative se concentrant sur un sous ensemble réduit des sujets étudiés afin d’affiner l’analyse et les conclusions.
Multi-méthodes
Un protocole multi-méthodes mélange plusieurs méthodes qui sont soit toutes quantitatives, soit toutes qualitatives.
Horizons temporels
L’horizon temporel défini le ou les moments auxquels les mesures seront faites et les données récoltées. On distingue les études transversales où les mesures sont faites à un (et un seul) moment dans le temps des études longitudinales où les mesures sont répétées à différent moments afin d’identifier une évolution. Ces mesures peuvent se faire sur un sous-ensemble d’une population (panel), sur un ensemble d’individus ayant une même caractéristiques (cohort) ou sur des archives histories (retrospective).
Techniques et procédures
Les techniques et procédures définissent les instruments concrets qui seront utilisés dans le protocole expérimental (par exemple, quels sont les questions posées pour une interview, quelles sont les outils de mesure utilisés pour la couverture de code, etc.), ainsi le moment auquel ils seront appliqués (avant l’utilisation de l’outils XYZ, après, pendant, etc.).
Une fois arrivé à ce stade, il est essentiel que le protocole soit exécutable par l’équipe de recherche, mais puisse également être (i) validé par les pairs (peer reviewing) afin d’identifier les problèmes potentiels et (ii) exécuté par une équipe externe afin de confirmer ou pas les résultats de manière indépendante. Pour rendre cela possible, il faut que le protocole fournisse suffisamment de détails sur la marche à suivre (c’est pour ces raisons que les articles de recherche incluent une description du protocole utilisé).
Protocoles de recherche en génie logiciel
Tout comme pour d’autres domaines, il existe une large variété de protocoles de recherche en génie logiciel basés sur différentes philosophies, approches et stratégies. Une récente initiative issue de la communauté de recherche en génie logiciel vise à la documentation et à la standardisation de l’évaluation par les pairs de ces protocoles : les Empirical Standards.
Chaque fiche fourni une description générale d’une stratégie, ainsi qu’une liste de critères indispensables et souhaitables pour les articles scientifiques décrivant une évaluation basée sur cette stratégie. Chaque fiche contient également une liste de pointeurs vers des suggestions de lecture pour approfondir la compréhension de la stratégie en question, ainsi que des exemples d’articles scientifiques ayant appliqué la stratégie de recherche de manière adéquate.
Resources additionnelles
- Arcuri, A., & Briand, L. (2014). A hitchhiker’s guide to statistical tests for assessing randomized algorithms in software engineering. Software Testing, Verification and Reliability, 24(3), 219-250.
- Les différentes fiches des Empirical Standards pointent vers un grand nombre d’exemples et de papiers de méthodologie.
- Awesome Empirical Software Engineering, un dépôt GitHub avec une liste organisée de jeux de données et d’outils pouvant être utilisés pour mener des recherches en génie logiciel.